I’ve recently made two large changes in the software stack that I use heavily in everyday life, and they were driven by AI: my note taking app and my personal finance app.
I’m still very fond of the apps that I’ve used for many years for each, but they had a key limitation that didn’t work for me anymore: They don’t expose their data directly. With AI, you really want to have direct, bidirectional (by which I mean both read/write) access to your data; and my new stack enables this.
Concretely, the switch was the following:
- Bear → Obsidian for note taking.
- YNAB → Moneten (a custom app I developed) for personal finance.
I’ll talk about both, because they cover two interesting use cases: note taking is mostly unstructured, messy data and personal finance is structured, organized data.
Note taking / unstructured data
I’ve used Bear for many years and I’m a big fan. The app is very polished, it works extremely well on Mac and iOS, and sync is fast and reliable.
However, it has one serious flaw: You cannot easily interact with its content programmatically. Bear stores all notes locally in a SQLite database. So reading from Bear is actually quite doable and I’ve had an MCP server for this for a while. But writing changes back into Bear is a non-starter. In fact, the Bear documentation explicitly warns users against modifying the SQLite database directly.
This turned out to be a severe design flaw for me: I want to be able to use AI tools to bidirectionally interact with my notes. I don’t want AI to write my notes (that defeats the purpose of note taking), but notes get messy and unorganized, and I’ve found that AI is amazing at cleaning up and organizing them. But I realized that I can’t do that with Bear, at least not straightforwardly.1
Very recently, Bear announced a CLI tool to make programmatic read/write access easier. They specifically cite AI tools as the main reason.
However, Bear’s data model is just fundamentally the wrong representation for notes. Notes are documents, and Bear uses Markdown. So my notes should just be Markdown files on disk. This really matters for using AI in practice: the agent can output a diff that gets applied to a text file, so updating a part of a note becomes extremely efficient and natural for agents. This isn’t possible for working with a database (or a CLI tool): The agent has to always output the whole note again.2
This is why I switched to Obsidian. It’s perfect for this. Obsidian just keeps around Markdown files on disk. They are the single source of truth and Obsidian is completely fine with other processes changing these files; it just monitors for changes and updates its UI.
Once I switched, I also realized that Claude Code / OpenAI Codex are very good at navigating folders of files. When they need to find things, they happily use ls, grep and find. So raw files aren’t just better for editing, but also for navigating the data.
I also got into the habit of using git for change tracking. Not in the sense that I commit my notes all the time when I make changes. But what I will often do looks something like this:
- I realize I want to do a clean-up / refactor using AI
- I
git commit everything
- I ask AI to do the refactor
- I can use
git diff to see exactly what was changed
- If necessary, I ask for corrections or revert
- Once I’m happy, I commit everything
This is an affordance that I get for free when using the file system. It works well and adds a safety net.
I’ve also built a simple linter that I run after AI changes to catch broken cross-reference links and other malformed data.
Personal finance / structured data
I’ve used YNAB since 2019 and I’ve categorized several thousand transactions for personal spend tracking. YNAB has served me really well over the years.
But my data lives on their server and I can only access it via a REST API. I want direct access to my data, and that means I want to have the raw database.
It also lacked a few features I cared about, like multi-currency support and investment tracking. So in the fall of 2025, I started developing my own personal finance app, which I call Moneten (a German word for money).
While I developed it, I had lots of missing features in the UI so I gave Claude Code access to the Postgres database and asked it to update the database accordingly (e.g. categorizing a transaction or moving a transaction to a different account). The way I do this is with a simple skill: it shows the agent how to connect to the database, describes the schema, and provides a few examples for common operations (categorizing transactions, linking transactions, counting transactions, …).
It turns out that this works amazingly well and I use it all the time now. My app has significantly progressed and most features have UI components, but it’s often easier and faster, especially for bulk operations, to use Claude Code to make changes. Below is a simple example (with the actual numbers masked for privacy reasons).
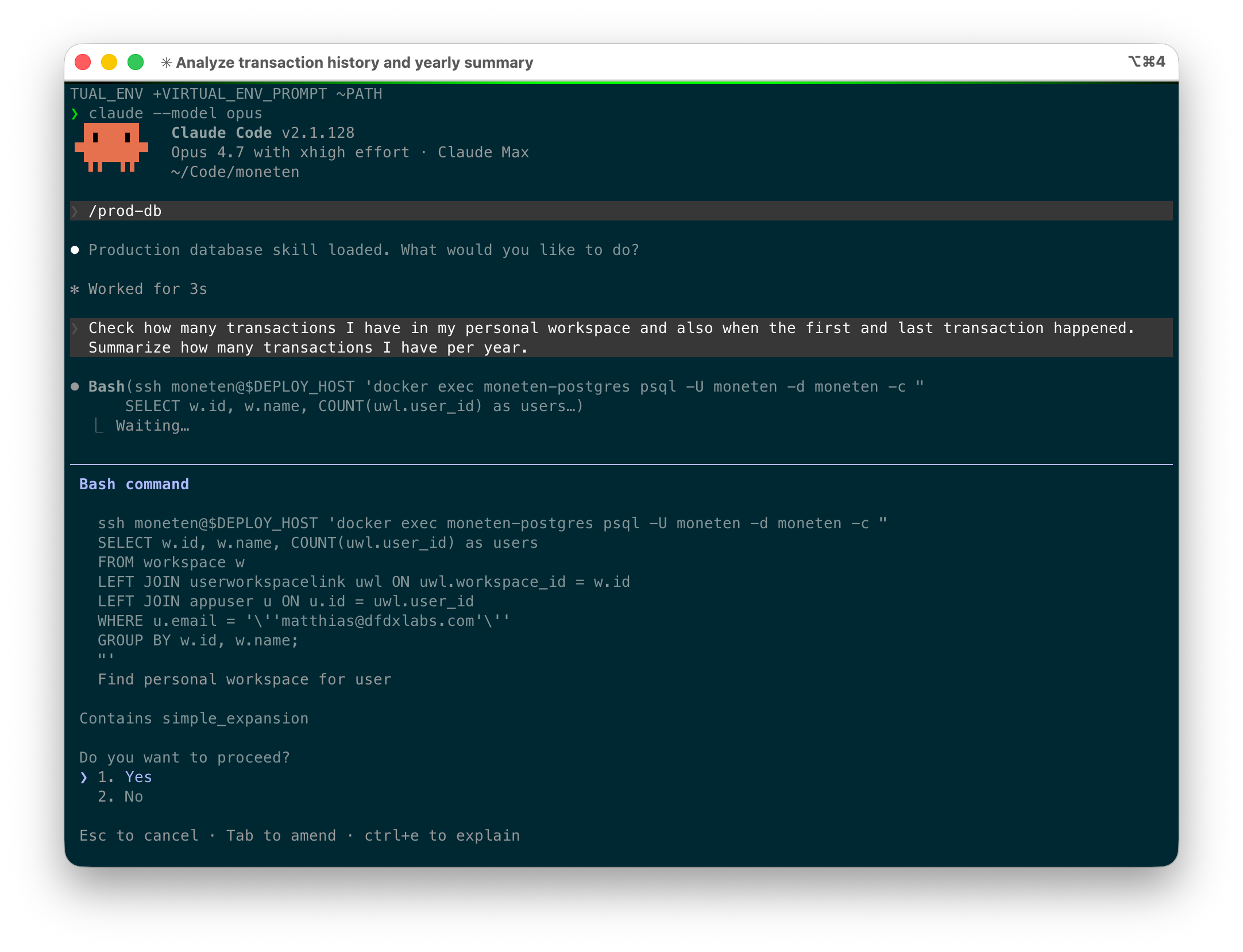
Notice how Claude Code executes raw SQL queries but asks before executing them (and I make sure to review them, especially if it’s not a SELECT query). After running a few of these, Claude Code arrives at the result.
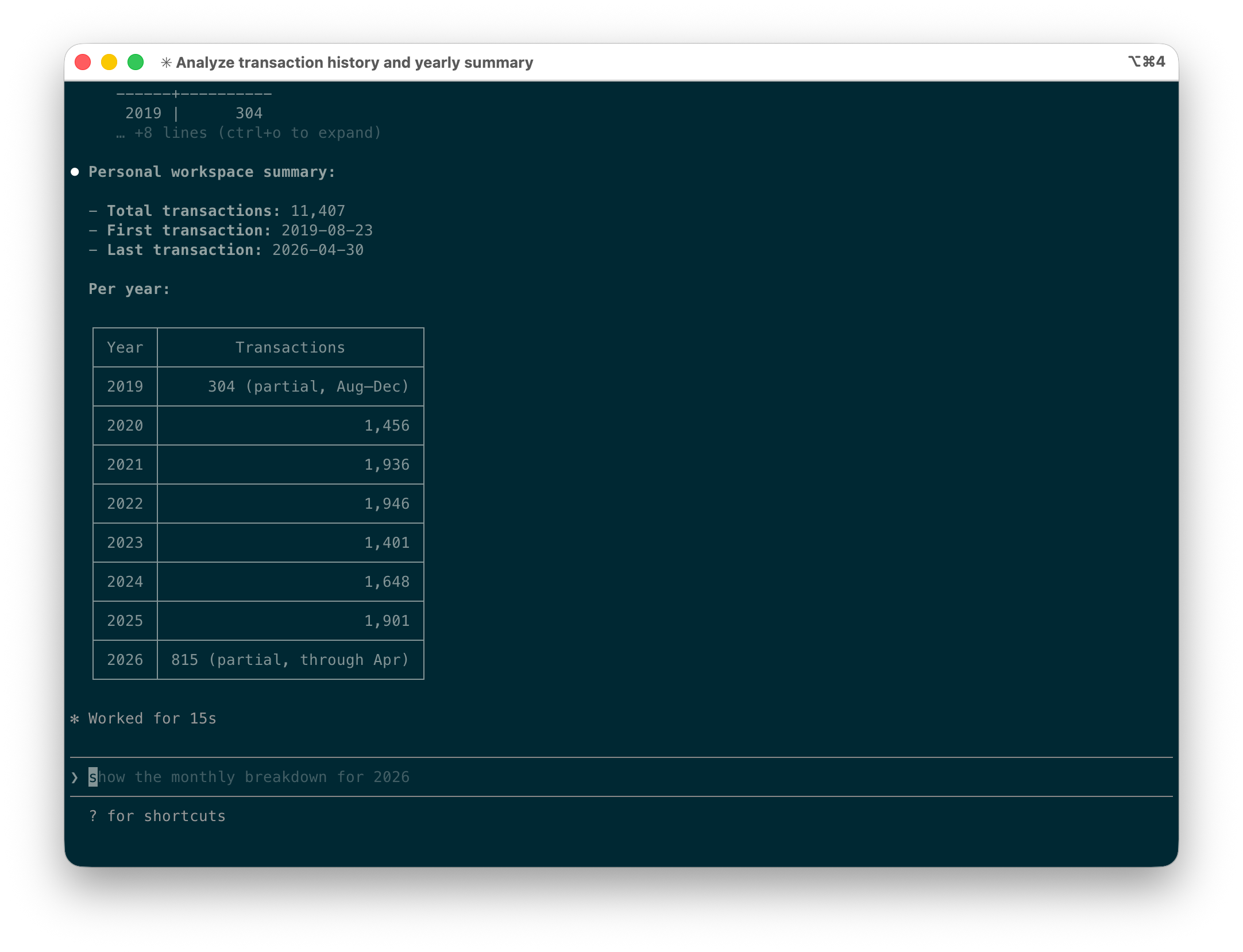
So, you might say, you are giving AI access to a production database 🤨? Yes, and I have to admit it feels slightly wrong.
However, I think it works in practice for the following reasons:
- The database only contains my own personal finance data. I would obviously never, ever do this if this were an app that is used by other people.
- I review each SQL query before executing it. I explicitly configured Claude Code to ask for permission for the corresponding bash command.
- I produce daily database backups and keep them around for a long time.
- I reconcile account transactions with the balance on my bank statements regularly, so I have natural checkpoints that would uncover incorrect balances.
- I enforce data model constraints at the database level, so the database cannot be in an inconsistent state. I think this one is key and Postgres is a great choice here with its support for triggers.
At the end of the day, I feel comfortable with the remaining risk for my use case and the benefit I get from raw database access is immense.
Imagine how much more cumbersome this would’ve been via an API: The agent would’ve had to request all transactions, then parse the date, then count them in memory. The right data model for structured data is a database.
However, I’ve noticed that I feel a lot more confident letting Claude Code edit my notes (since they are versioned under git) vs. letting it loose on my personal finance database (which is not versioned, so I need to make sure the commands it runs are reasonable).
Takeaways
AI wants to be as close as possible to your data: raw data > cli / mcp / api > gui. Local matters less than you’d think; what matters is direct access. Bear’s database is local but I can’t directly modify it, so it doesn’t help.
For unstructured data, use raw text files; coding agents are great at finding and editing them. For structured data, use raw database access; you simply can’t get the same expressiveness via a CLI or API. The database route is an obvious risk, so it only works if the database contains only your data and you trust yourself to do it responsibly.
For write access, you either review and approve every AI change, or you need versioning so you can see what changed and revert. For text files this is solved: just use git. For databases it’s largely unsolved in the mainstream. Dolt shows it’s possible—a MySQL-compatible database with git-style branching, diffing, and merging on row data—but nothing comparable exists for Postgres or SQLite, where most personal data actually lives. There’s ample opportunity for more innovation here.
{kind=link}